因为教书,所以,在讲解相关的概念和技术的时候,总是习惯首先从大处着眼,然后在小处入手。所谓从大处着眼,就是梳理下概念和技术的源流和历史;在小处入手就是总是使用具体的例子来讲解。
前面也谈AI简史简单梳理了AI(作为人类追寻智慧的一部分)的Big Picture(还真没找到合适的描述 - 大图景?怪怪的);此文简要梳理下AI的核心技术 - 优化(注意:不仅仅是优化论)。如果你不了解点优化的知识,还真够呛能深入AI,尤其是机器学习(Machine Learning),以及现在的火热的深度学习(Deep Learning)。
要强调的是:真正想要精通机器学习,意味着你必须要了解优化!
还有:此处涉及到的数学知识,仅作陈述,不再给出证明!如对证明感兴趣,请自行搜索。
优化,及其简要的历史
所谓优化(Optimization) - 无处不在
这个…还真不好说,因为涉及的太多了。简单地说,所谓优化,宽泛地说,就是找到需要解决的问题的最佳方案。
问题有很多:大到宇宙到底是如何形成和演化的?,小到某种茶用水的最佳温度?。在尝试解决这类问题的过程中,会提出很多的方案。优化,就是找到那个最佳的方案。
我就曾经对所谓 大爆炸理论存有疑问:大爆炸理论的基点是设定有那么一个点,突然爆炸诞生出了现在我们认知的宇宙里的所有的物质。我的存疑就是,如果那个点其实是一个通道的入口,也同样可以妥善地解释那些支撑大爆炸的所谓的现象。
可是,那个通道…现在(甚至是很久以后的将来)仍然会是很难验证的:就像自带循环系统里的鱼,你能感受到因为循环带来的水流的变化,你就会假定
噢,所有的水都是从一个点大爆炸来的。
所谓科学,也是与此类似的。有时候基于观察到的提出假设,然后,就是看看哪种解释最为合理而已。
而与AI和ML的学习紧密相关的优化,则是依赖于数学手段的处理方式,尤其是依赖于数学分析的优化(突出的代表就是凸优化),也是此文所关注的。
优化的简要历史
按照上面对优化的理解,那么,优化的历史就很久了!大致分为三个时期(个人观点):数学分析出现之前,数学分析和变分法时期,以及非线性时期。
数学分析,简单地说,就是高等数学对应的内容(当然,大学的高等数学其实也只算是基础,帮助你了解该领域的概念和术语而已)。其在数学史中的地位毋庸讳言,也因之为优化提供的强大的武器。所以,觉得以之来划分是恰当的。
数学分析出现之前 - 举几个例子而已
300 BC - 欧几里得的 Isoperimetric rectangle with greatest area
定理的陈述很简单,”边长固定,在长方形中,正方形(正方形是长方形的特例)面积最大”。但是,那是在公元前300年!你试试?
100 BC, Heron Catoptrica, Light travels shortest path off mirror

这一时期的优化,很多时候是依赖个人的灵性,没有一套比较好的数学套路来完美求解那些问题。这得一直到数学分析这一强大的工具出现后才得以突破。
数学分析和变分法时期 - 以凸优化为代表
数学分析的历史就不赘述了 - 网上有很多的趣闻和轶事(关于牛顿和莱布尼兹,关于欧拉的工作等)。数学分析的重要性毋庸置疑,它也大大促进了优化问题的求解(如果可以使用数学分析的方法求解的话)。在这里不得不提的是所谓的变分法(Calculus of Variations)。感兴趣的话可以自己找找看 ,在此只是给出下面的示例,以助于读者直观感受下。
变分法最终寻求的是极值函数:它们使得泛函取得极大或极小值。
有些曲线上的经典问题采用这种形式表达:一个例子是最速降线,在重力作用下一个粒子沿着该路径可以在最短时间从点A到达不直接在它底下的一点B。

数学分析的技术用于优化,其思想还是很简单的(说过:证明其正确性才是挑战!),主要的就是极值定理:通过函数的一阶和二阶导数的性质,可以确定不动点(Stationary Point)是局部极大还是极小。
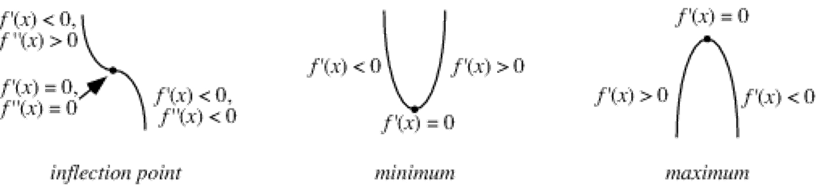
这一现象在多元变量函数上也有类似的规律,留到后面(凸)优化的框架再做介绍。
此外,当函数是凸函数的时候,极值点(不动点)也就是该函数的全局极值了。也留到后面(凸)优化的框架再做介绍。
需要强调的是:数学分析并不就能用于解决所有的优化问题,只是因为它解决问题的
优美,让人不能等闲视之。不过,还有很多优化问题不能使用解析法(数学分析)来求解,这类问题的求解方法总结一般归入所谓的运筹学(Operational Research)。这也是学习优化的读者不应忽略的。

非线性时期,和其它更复杂的问题
说起来,简单点的优化问题解决的还是不错的,其集大成者就是所谓的凸优化。不过,问题有时候总是比方法多!现实中还有许多的问题是在凸优化覆盖的范畴之外的。

上图是网上找到的了关于优化论覆盖的问题范畴:整个矩形对应所有的优化问题,其中的CP就是 Convex Programming (凸规划问题。在数学领域往往习惯成为Convex Optimization),PP对应多项式规划(Polynomial Programming)问题(要注意,PP中有些问题会是非线性的),此外就是非线性问题了。而且非线性问题更多。反过来说,非线性优化问题才是很难的问题。
不过,难问题毕竟是难,按照陆吾生先生的说法,PP现在得到了很大的关注,就是因为它覆盖了部分的非线性问题。相关的研究就想从这类非线性问题的求解中找找规律,以推进对其他非线性问题的求解。
另一方面,大规模的全局优化问题,也得益于计算机的发展有了有趣的推进,1980年代提出了Genetic Algorithm [遗传算法],Simulated Annealing Algorithm[模拟退火算法],Ant Algorithm [蚁群算法]等方法。
(凸)优化的框架
准备知识:极值定理到多元函数的拓展
在前面知道,对于一元函数而言,极值定理既能够帮助我们求解极值点(一阶导数为零的点,也就是局部最优点。仅当函数是凸函数时,才是全局最优点),在极值点的二阶导数能够进一步确定极值点的性质(是极大还是极小)。
这种现象在多元变量函数中也存在,分别对应一阶偏导数和Hessian 矩阵(对应一元函数的二阶导数)。下面只是给出个例子体会下,更深入的理论请自行查找。

凸优化问题的统一描述
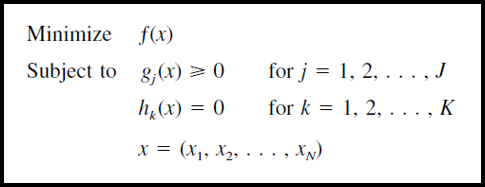
其中,f(x)是目标函数;g(x) 是不等约束条件;h(x) 是等值约束条件;x是多元变量的向量形式。
** 注意:这种描述也同样适用于 被CP覆盖的其他形式的优化问题。
** 强调:后面描述的求解套路并不适用线性规划(Linear Programming)。为什么?因为线性规划的一阶导数是常数 ![]()
三个层次
无约束问题
无约束问题,也就是只有一个目标函数,而没有任何约束条件。这类问题的求解,就是求解一阶和二阶的套路:一阶定极值,二阶定性质。
等值约束 - 借助拉格朗日乘子转换为无约束求解
也就是只含有等值约束的问题。这类问题的求解就需要所谓的拉格朗日(Lagrange Multiplier)算子的帮助,借助它能将此类问题的求解转化为无约束问题的求解。

在构造了拉格朗日函数后,分别对两个变量求一阶偏导数,然后再加上等式条件,我们就有三个方程和三个变量(新引入的ν变量就是所谓的拉格朗日乘子),也就可以求的三个变量的值。

在得到三个变量的值后,进一步求解兰格朗日函数在两个点处的二阶偏导数(也就是黑森矩阵 - Hessian Matrix),进而可以知道黑森矩阵的性质 - 正定,负定,还是不定。由于此优化问题是求解目标函数的最小,那么,对应正定黑森矩阵的点也就是最小值了。
不等或混合约束 - 通常按照KKT这一最优点的必要条件来求解
一定要记住:KKT 是求解不等约束问题的必要条件!
注意:此处仅仅简单地给出概貌和样例,不做数学证明!证明确实很难的!






关于KKT的一点逸闻:
1951年 Harold W. Kuhn 和 Albert William Tucker 发现了此条件并撰写了论文将其正式发表出来[1],引起了很多学者的重视。自此之后一些学者发现早在1939年 William Karush 在其硕士学位论文[2]里边已经给出了KKT条件,只是由于当时没有引起研究者的广泛关注而已。因此Kuhn ,Tucker,Karush 三位都作为独立发现此条件的学者,这个最优性条件就以他们三个人的名字来命名(KKT)。
[1] Harold W. Kuhn; Albert William Tucker (1951). “Nonlinear programming”. Proceedings of 2nd Berkeley Symposium. Berkeley: University of California Press. pp. 481–492. MR 0047303.
[2] William Karush (1939). “Minima of Functions of Several Variables with Inequalities as Side Constraints”. M.Sc. Dissertation. Dept. of Mathematics, Univ. of Chicago, Chicago, Illinois.
(凸)优化的数值求解
有了前面的理论,想要手工实际得到结果仍然是很费劲的,好在有计算机。不过,下面提到的各种计算机算法(数值方法)主要是针对前两个层次的求解,不等约束问题的求解,因为依赖具体的情况(前面例子里的很多Cases),所以很难有统一的求解算法。
梯度下降(Gradient descent method)和最速(梯度)下降法(SGD: Steepest Gradient Descent)
梯度下降法(Gradient descent),顾名思义,就是自变量沿着梯度向量的反方向进行移动,因为梯度的方向是上升的方向。

最速下降法(Steepest descent)是梯度下降法的一种更具体实现形式,其理念为在每次迭代中选择合适的步长,使得目标函数值能够得到最大程度的减少。

机器学习中的梯度下降法
对于机器学习中的分类问题,都需要基于数据来训练所选模型的参数(不管是著名的支持向量机,还是神经网络的参数训练 - 从简单的感知机到现在火热的深度学习)。

假设训练集中含有 N 个数据样本,对上面的的 n 取不同值(即一次性计算 loss 的样本个数取不同值),实际计算时会有不同的影响。如果 n=1,这就是 随机梯度下降法(Stochastic Gradient Descent);如果 1<n<N,这就是 小批量梯度下降法(mini-batch gradient descent。batch size 一般不会很大);如果 n=N,这就是(批量)梯度下降法([Batch] gradient descent)。
牛顿法 (Newton’s method)
在确定搜索方向时,梯度下降和最速下降只用到了目标函数的一阶导数(梯度),而牛顿法(Newton’s method)用到了二阶(偏)导数。

很多其它的方法
其他的求解方法还有很多,比如共轭梯度法(Conjugate Gradient Method), 拟牛顿法(Quasi Newton)等,请自行搜索。
对求解参数的规整
前面提到了机器学习中的梯度下降法,有时候为了使得所得到的的参数满足某些预设的要求,会人为引入所谓的正则项。比较有名的是LASSO, 好的Ridge 等。
LASSO,即Least Absolute Shrinkage and Selection Operator的简称,是一种采用了L1正则化(L1-regularization)的线性回归方法,采用了L1正则会使得部分学习到的特征权值为0,从而达到稀疏化和特征选择的目的
LASSO是Tibshirani(对就是Tibshirani)在1996年JRSSB上的一篇文章上《Regression shrinkage and selection via lasso》提出的。所谓lasso,其全称是least absolute shrinkage and selection operator,其含义是在限制了的情况下,求使得残差平和达到最小的参数的估值。
如果惩罚项是参数的L2范数,就是脊回归(Ridge Regression),又叫岭回归。
与优化有关的奖项
在优化研究领域,有两个著名的国际奖项,George B. Dantzig Prize 和 John von Neumann Theory Prize。
[George B. Dantzig Prize] The Dantzig Prize was founded by a group of George B. Dantzig’s former students (R. W. Cottle, E. L. Johnson, R. M. van Slyke, and R. J.-B. Wets) and was first awarded in 1982.
[John von Neumann Theory Prize] The John von Neumann Theory Prize of the Institute for Operations Research and the Management Sciences (INFORMS) is awarded annually to an individual (or sometimes a group) who has made fundamental and sustained contributions to theory in operations research and the management sciences. It is regarded the “Nobel Prize” of the field.
George B. Dantzig is the 1st winner of this prize (1975)
最后是几本书
- An Introduction to Optimization (最优化导论): 本书是一本关于最优化技术的入门教材,全书共分为四部分。第一部分是预备知识。第二部分主要介绍无约束的优化问题,并介绍线性方程的求解方法、神经网络方法和全局搜索方法。第三部分介绍线性优化问题,包括线性优化问题的模型、单纯形法、对偶理论以及一些非单纯形法,简单介绍了整数线性优化问题。第四部分介绍有约束非线性优化问题,包括纯等式约束下和不等式约束下的优化问题的最优性条件、凸优化问题、有约束非线性优化问题的求解算法和多目标优化问题。
- Convex Optimization:Stephen Boyd and Lieven Vandenberghe. Convex Optimization. Cambridge University Press. 免费。偏重于理论,也就是要用严格的数学证明为什么书中的求解是正确的。我个人的体会:方法的构建很多时候是不难的-试错而已,难在如何证明!
- Optimization Models:by Giuseppe C. Calafiore, Laurent El Ghaoui. Emphasizing practical understanding over the technicalities of specific algorithms, this elegant textbook is an accessible introduction to the field of optimization, focusing on powerful and reliable convex optimization techniques.
- Practical Optimization: Algorithms and Engineering Applications:陆吾生先生参与著作的书,支持一下。


