统计推断下的商务决策
因为教书,所以,在讲解相关的概念和技术的时候,总是习惯首先从大处着眼,然后在小处入手。所谓从大处着眼,就是梳理下概念和技术的源流和历史;在小处入手就是总是使用具体的例子来讲解。这样,才能既有对相关专题的宏观把握,又能直观地领会背后的数学。
统计学
了解统计学思想更为有趣,其实也更为重要
统计学,想来理工科的人都学习过。不过,可能也都有头疼的感觉:似乎学习统计学就必须先学习概率论,可概率论就像一座山,想要弄懂并不容易(我要承认,我是没有深入体会的)。
因为自己学习某一理论总是习惯了解其后的历史,所以,也了解到统计学早期的一些有趣的轶事。知道,最早使用统计学来认知社会现象的时候,并不是学会了概率论才行的。更像是,先做了,然后才是夯实理论基础 - 这在数学发展的过程中是屡见不鲜的。
约翰 · 格朗特(1620-1674)。他以 1604 年伦敦教会每周一次发表的 “死亡公报” 为研究资料,在 1662 年发表了《关于死亡公报的自然和政治观察》的论著。书中分析了 60 年来伦敦居民死亡的原因及人口变动的关系,首次提出通过大量观察,可以发现新生儿性别比例具有稳定性和不同死因的比例等人口规律;并且第一次编制了“生命表”,对死亡率与人口寿命作了分析,从而引起了普遍的关注。他的研究清楚地表明了统计学作为国家管理工具的重要作用。
1654年,两位法国数学家帕斯卡和费马通过通信讨论解决了由赌徒分配赌金引起的”点数问题”,才标志着概率论的诞生,因此公认的概率论创始人是帕斯卡与费马。
比利时的阿道夫 · 凯特勒(1796-1874)在19 世纪中叶正式把古典概率论引进统计学,使统计学进入一个新的发展阶段,其主要著作有:《论人类》、《概率论书简》、《社会制度》和《社会物理学》等。他主张用研究自然科学的方法研究社会现象。
所以,了解统计学的思想,并不需要严格的概率论的知识。不过,现在的书籍大多秉承了倒叙的方式,总是将后来的解释- 也就是理论基础先说一大堆,然后才是严谨地将鲜活的统计学思想妥善地隐藏在纷繁复杂的各个章节中。很多时候,学习统计学的人在概率论就已经死去了 ![]()
其实,统计学的很新内容是很简洁明了的,也就是基于分布的小概率逻辑推断而已。
核心就是基于分布的小概率逻辑推荐
我们都有这样的经历,当你习惯了每天某一时刻会发生某件事时(如日出日落),突然有一天此事不再发生,你必然会觉得很奇怪,会推测是不是因为什么原因导致了此事在今天没有发生。
其实,将此种现象在数学(统计学)中提炼出来就是小概率事件(Small Probability Event)。为了量化这样的概念,统计学中做了严谨的理论构建,也就是概率论等的价值所在。
为此,统计学理论的基本任务就是:
- 某一事件发生的分布(Distribution)。
- 所谓的分布,简单地讲就是事件发生的频率。如果事件有多种取值,每一值也就有对应的频率。这也是早期概率的定义。常见的有四种分布 - 也就是后面正态,学生,卡方和费舍尔
- 这里有个问题,那就是如何获得分布。除了一些理论可以推定的,很多现实中的问题都是通过样本来推定总体的分布的。那么,这种推定是否正确?这就是学者要证明的 - 很多时候就需要数学家了。概率论便是这类学者要用到的工具。
- 基于小概率事件(SPE)进行推断
- 有了前面的分布,在指定事件取值的主要区间(按照设定的规则,可以建立取值区间与可能程度 - 也就是概率 - 的对应关系,即给定98%的可能程度,就有对应的取值范畴),那么,剩下的取值范畴就是所谓的小概率事件的范畴,每一个被小概率事件的范畴覆盖的取值就是小概率事件了。
- 所谓小概率事件的意义就在于,按照事件取值的可能程度,小概率事件发生的可能性是很低的。如果有一次抽查就遇到了小概率事件,也就是”不应该发生的发生了”,这就意味着有两种推断:
- 原来的分布是有问题的
- 此次事件是有特殊的原因导致的
常见统计学书籍的章节虽然很多,其实都是可以从上面衍生出来的。
基本的四个分布 - 正态,学生,卡方和费舍尔
以正态分布为例
下图即为标准正态分布(Standard Normal Distribution)的示意。横坐标上就是随机变量(与事件是绑定的)的取值;那个钟型曲线覆盖下的面积就是对应于相应取值范畴的可能程度(概率)。例如,变量取值在[0, 0.5]时,概率是19.1%。
 对于像正态分布这类的对称形状,如果指定以0点所在的位置对称向左右等距扩展作为规则,得到的区间和概率是一一对应的。如,[-1,1]对应的概率就是2*(15+19.1) = 30+38.2 = 68.2%。此时,-1和1就是概率68.2%所对应的的关键值(Critical Value)。
对于像正态分布这类的对称形状,如果指定以0点所在的位置对称向左右等距扩展作为规则,得到的区间和概率是一一对应的。如,[-1,1]对应的概率就是2*(15+19.1) = 30+38.2 = 68.2%。此时,-1和1就是概率68.2%所对应的的关键值(Critical Value)。
而按照惯例,我们通常会指定比较大的概率(常用的多是大于或等于95% - 如95%, 96%, 98%等)作为事件可能取值的极大可能程度,在统计学中称为置信度(Confidence Level)。如下图所示:95.4%是很大的概率了,对应的关键值是-2和2,[-2,2]也就是统计学书籍中对应95.4%置信度的置信区间(Confidence Interval)。
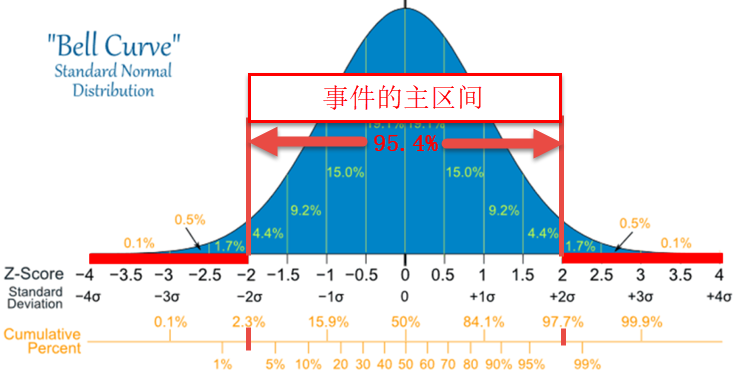
对应的,排除在置信区间之外的可能取值范畴就是我们所感兴趣的小概率事件区间(SPE Interval)。如下图示。如果再一次抽样中得到的统计变量的值落入此小概率事件区间中,那么,按照核心就是基于分布的小概率逻辑推荐中的叙述,我们就有理由做两种推断了。

剩下的就是如何计算给定置信度下的置信区间。这也是统计学书籍的主要内容。感谢前人的艰苦付出,他们完成了很多分布的计算表格,如果你遇到计算给定置信度下的置信区间的问题,去查表即可。
说起来,统计学的基本内容也就是围绕着两个计算问题展开的:
- 如何基于样本计算分布的参数
- 计算给定置信度下的置信区间
正态分布下求解双尾置信区间的例子
下面给出一个求解置信度95%的双尾(2 Tails,也就是要求对称的置信区间。与之对应的是单尾,即对应置信度95%的单尾置信区间是从-∞到关键值)置信区间的例子。想要完成计算,就必须了解如何使用计算表(Table of Normal Distribution)。

想要准确使用计算表,就要注意与表格对应的示意图(Indicator)。上面图中左侧就是对应的示意图,表示对应[0,0.45]的概率是0.1736,即计算表格中深蓝色箭头所示意的。
如果想要求解置信度95%的双尾置信区间,也就是要求找到某个x值,[-x,x]区间上的概率恰好就是95%。想要使用上面的计算表格完成x的查找,就要做一点小小的转换。
因为正态分布是对称的,那么,[-x,x]区间上的高绿要保证是95%,也就意味着[0,x]区间上的概率必须是95%的二分之一,即47.5%=0.4750。查表得到x=1.96。即置信区间是[-1.96,1.96]。
注意:此处的示例是对应标准正态分布的计算。不过,实际正态分布变量的置信区间计算也很简单,就是借助正态分布到标准正态分布的转换公即可,也就是上图中左侧示意图下面所标识的公式,其中z对应标准正态分布变量,x是实际的变量(当然要要确保x是正态分布),μ和σ是正态分布的两个参数 - 均值和标准方差。
Example: Your business – Quality Control:
Your company is majoring to produce some products, whose size is firmly required: μ=21 mm, and the variance should be smaller than σ≤0.1 5 mm. Today, you pick 9 products from that collection, and measure the average length of those 9 products is 21.4 mm. Are you confident (95%-2 tail) with the quality of your products?
Solution:

其他分布
前面提到,统计学的基本内容是依赖于分布的,一般教科书中提到的主要就是四种分布 - 前面的正态分布,学生分布,卡方分布,以及费舍尔分布。
如下图所示,针对不同的统计变量,就会有已经证明了的统计分布与之相对应;而剩下的计算也仍然是前面介绍的套路:或者估计相应分部的参数;或者计算给定置信度的置信区间,然后进行推断。

其中比较有趣的是所谓的ANOVA - ANalysis Of VAriance (方差估计)。虽然名字里有方差一次,实际的应用跟方差没啥关系。有兴趣的请自行检索。
统计学章节概览
在有了前面的储备后,看看常见的统计学的书籍,也就没那么障碍了。
[概率论与数理统计]
https://book.douban.com/subject/2201479/作者: 陈希孺 出版社: 中国科学技术大学出版社 出版年: 2009-2 页数: 385 定价: 38.00元 丛书: 陈希孺文集 ISBN: 9787312018381
| 章节目录 | 备注 |
|---|---|
| 总序 序 第1章 事件的概率 第2章 随机变量及概率分布 第3章 随机变量的数字特征 |
概率论的东西 |
|
第4章 参数估计 4.1 数理统计学的基本概念 4.2 矩估计、极大似然估计和贝叶斯估计 4.3 点估计的优良性准则 4.4 区间估计 |
对应分布的估计,显然包括区间估计的计算 |
|
第5章 假设检验 |
其实是基于小概率事件逻辑推断的一种描述而已,核心的计算仍然是小概率区间。 当基于样本得到的值落在小概率区间,则推翻零假设;否则不能推翻 切记:不能推翻零假设,并不意味着就证明零假设是对的! |
|
第6章 回归、相关与方差分析 6.1 回归分析的基本概念 6.2 一元线性回归 6.3 多元线性回归 6.4 相关分析 6.5 方差分析 |
这里的内容都会发现完成复杂的运算,而基于分布的计算部分仍然是类似的 例如线性回归后估计预测的可信度;相关分析是否可信;ANOVA 能否否定产品不同设计与销售没有关系,等 |
| 附录 习题 习题提示与解答 附表 |
其实,还有一些统计学书籍也会讲因子分析、PCA等内容纳入。不赘述 |
多元统计分析章节概览
[应用多元统计分析]
https://book.douban.com/subject/1239695/作者: 高惠璇 出版社: 北京大学出版社 出版年: 2005-1 页数: 419 定价: 28.00元 装帧: 简裝本 丛书: 北京大学数学教学系列丛书 ISBN: 9787301078587
| 目录 | 备注 |
|---|---|
| 第一章 绪论 第二章 多元正态分布及参数的估计 第三章 多元正态总体参数的假设检验 第四章 回归分析 |
嗯,虽则内容肯定不同;但套路应该还是类似的 |
| 第五章 判别分析 §5.1 距离判别 §5.2 贝叶斯(Bayes)判别法及广义平方距离判别法 §5.3 费希尔(Fisher)判别 §5.4 判别效果的检验及各变量判别能力的检验 §5.5 逐步判别 习题五 |
这在数据挖掘(Data Mining)里会归入分类,在机器学习(Machine Learning)里归入指导下的学习算法(Suppersized Learning) |
| 第六章 聚类分析 §6.1 聚类分析的方法 §6.2 距离与相似系数 §6.3 系统聚类法 §6.4 系统聚类法的性质及类的确定 §6.5 动态聚类法 §6.6 有序样品聚类法(最优分割法) §6.7 变量聚类方法 |
这在数据挖掘(Data Mining)里会归入聚类,在机器学习(Machine Learning)里归入无指导下的学习算法(Unsuppersized Learning) |
| 第七章 主成分分析 §7.1 总体的主成分 §7.2 样本的主成分 §7.3 主成分分析的应用 |
就是PCA了,不依赖分布了 |
| 第八章 因子分析 §8.1 引言 §8.2 因子模型 …… |
不要跟基于回归的影响因子分析相混淆。 |
| 第九章 对应分析方法 |
以后再了解吧 |
| 第十章 典型相关分析 |
相关呀 |
| 第十一章 偏最小二乘回归分析 |
这是从优化论的角度计算回归问题 |
| 附录 矩阵代数 部分习题参考解答或提示 参考文献 主要符号说明 索引 |
个人觉得,多元统计分析,很多内容已经跟后来的数据挖掘和机器学习相重合了。已经不是严重依赖分布的统计学传统套路了。不过,这类方法也仍然称之为统计学习(Statistical Learning)
[统计学习方法(第2版)]
https://book.douban.com/subject/33437381/
统计学习方法
[统计学习方法(第2版)]
https://book.douban.com/subject/33437381/作者: 李航 出版社: 清华大学出版社 出版年: 2019-5-1 页数: 464 定价: 98.00元 装帧: 平装 ISBN: 9787302517276
目录 第一篇 监督学习
第二篇 无监督学习 第13章 无监督学习概论 13.1.1 无监督学习基本原理 13.1.2 基本问题 13.1.3 机器学习三要素 13.1.4 无监督学习方法
第14章 聚类方法 14.1 聚类的基本概念 14.1.1 相似度或距离 14.1.2 类或簇 14.1.3 类与类之间的距离 14.2 层次聚类 14.3 k均值聚类 14.3.1 模型 14.3.2 策略 14.3.3 算法 14.3.4 算法特点 本章概要
第15章 奇异值分解 15.1 奇异值分解的定义与性质 15.1.1 定义与定理 15.1.2 紧奇异值分解与截断奇异值分解 15.1.3 几何解释 15.1.4 主要性质 15.2 奇异值分解的计算 15.3 奇异值分解与矩阵近似 15.3.1 弗罗贝尼乌斯范数 15.3.2 矩阵的优近似 15.3.3 矩阵的外积展开式 本章概要
第16章 主成分分析 16.1 总体主成分分析 16.1.1 基本想法 16.1.2 定义和导出 16.1.3 主要性质 16.1.4 主成分的个数 16.1.5 规范化变量的总体主成分 16.2 样本主成分分析 16.2.1 样本主成分的定义和性质 16.2.2 相关矩阵的特征值分解算法 16.2.3 数据局正的奇异值分解算法 本章概要 继续阅读 习题 参考文献
第17章 潜在语义分析 17.1 单词向量空间与话题向量空间 17.1.1 单词向量空间 17.1.2 话题向量空间 17.2 潜在语义分析算法 17.2.1 矩阵奇异值分解算法 17.2.2 例子 17.3 非负矩阵分解算法 17.3.1 非负矩阵分解 17.3.2 潜在语义分析模型 17.3.3 非负矩阵分解的形式化 17.3.4 算法 本章概要
第18章 概率潜在语义分析 18.1 概率潜在语义分析模型 18.1.1 基本想法 18.1.2 生成模型 18.1.3 共现模型 18.1.4 模型性质 18.2 概率潜在语义分析的算法 本章概要
第19章 马尔可夫链蒙特卡罗法 19.1 蒙特卡罗法 19.1.1 随机抽样 19.1.2 数学期望估计 19.1.3 积分计算 19.2 马尔可夫链 19.2.1 基本定义 19.2.2 离散状态马尔可夫链 19.2.3 连续状态马尔可夫链 19.2.4 马尔可夫链的性质 19.3 马尔可夫链蒙特卡罗法 19.3.1 基本想法 19.3.2 基本步骤 19.3.3 马尔可夫链蒙特卡罗法与统计学习 19.4 Metropolis-Hastings算法 19.4.1 基本原理 19.4.2 Metropolis-Hastings算法 19.4.3 单分量Metropolis-Hastings算法 19.5 吉布斯抽样 19.5.1 基本原理 19.5.2 吉布斯抽样算法 19.5.3 抽样计算 本章概要
第20章 潜在狄利克雷分配 20.1 狄利克雷分布 20.1.1 分布定义 20.1.2 共轭先验 20.2 潜在狄利克雷分配模型 20.2.1 基本想法 20.2.2 模型定义 20.2.3 概率图模型 20.2.4 随机变量序列的可交换性 20.2.5 概率公式 20.3 LDA的吉布斯抽样算法 20.3.1 基本想法 20.3.2 算法的主要部分 20.3.3 算法的后处理 20.3.4 算法 20.4 LDA的变分EM算法 20.4.1 变分推理 20.4.2 变分EM算法 20.4.3 算法推导 20.4.4 算法总结 本章概要
第21章 PageRank算法 21.1 PageRank的定义 21.1.1 基本想法 21.1.2 有向图和随机游走模型 21.1.3 PageRank的基本定义 21.1.4 PageRank的一般定义 21.2 PageRank的计算 21.2.1 迭代算法 21.2.2 幂法 21.3.3 代数算法 本章概要
第22章 无监督学习方法总结 22.1 无监督学习方法的关系和特点 22.1.1 各种方法之间的关系 22.1.2 无监督学习方法 22.1.3 基础及其学习方法 22.2 话题模型之间的关系和特点 参考文献
附录A 梯度下降法 附录B 牛顿法和拟牛顿法 附录C 拉格朗日对偶性 附录D 矩阵的基本子空间 附录E KL散度的定义和狄利克雷分布的性质
索引
题外话
仍然是:证明才难!不过,先体会整体框架也同样重要!!
那些分布函数的由来
了解一下分布的由来也很有趣
- [正态分布的前世今生]
- [数理统计学简史]
https://book.douban.com/subject/1522839/
涉及经济民生的那些指数
CPI,GDP之类
还有股票市场的那些指数
一些有趣的视频
BBC拍了几部有关数据分析的视频,值得看看
- 2010.BBC.乐在其中统计学.The.Joy.of.Stats
- 2013.BBC.地平线.大数据时代.horizon.the.age.of.big.data
- 2016.BBC.The.Joy.of.Data
最后是几本专业书
- [Statistical Methods for the Social Sciences, 4/E]
https://book.douban.com/subject/3868520/ - [应用多元统计分析]
https://book.douban.com/subject/1239695/ - [实用多元统计分析]
https://book.douban.com/subject/3519805/